この項の問題点
この項は未完成であり重大な間違いを含んでいる可能性があります。(2009-08-09)
概要
naive Bayes modelはクラスが与えられた時、各attributeが条件付独立となるモデルです。(naiveがかかるのはmodelであってBayesではありません。念のため。)

と

の同時確率は以下の式で表されます。
以下はBayesian networkでの表現です。
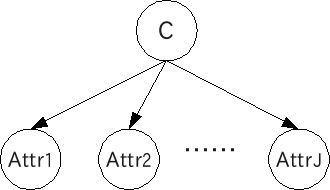
EMアルゴリズムによるパラメータ推定
EMアルゴリズムの

は以下の形。

はcategorical distributionにしたがうとします。
つまり

と表し、

を満たします。
mixture modelの時と同様に更新式は以下の形になります。
ある

において

がcategorical distributionにしたがう場合を考えます。

と表し、

を満たします。
と同様に更新式は以下の形になります。
ただし

は

を満たす時1を、それ以外は0をとるとします。
ある
において
が多次元正規分布(multivariate normal distribution)にしたがう場合を考えます。
これもmixture modelの時と同様です。
最終更新:2010年01月21日 08:02

